
Diffusion in language models, and rethinking thought
Published:
Introduction
Most LLMs today are autoregressive, meaning that they generate each token one at a time, step-by-step, only after seeing the previous token.
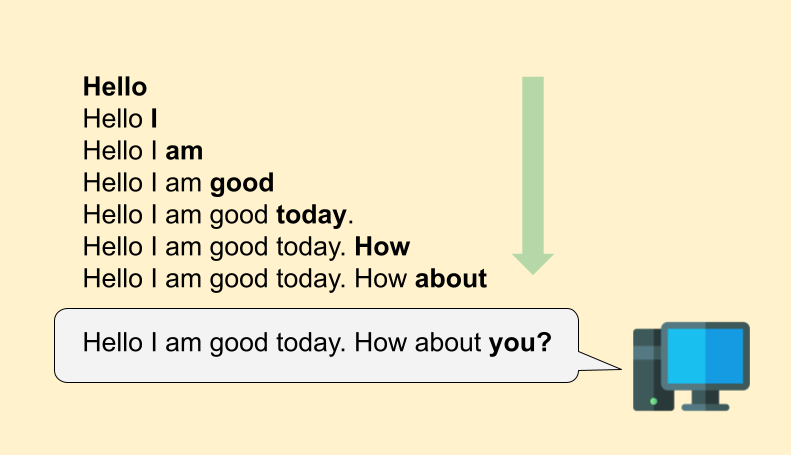
You might be thinking, duh? Of course an LLM only generates a token after it generated the one before it. As humans, that is also how we read, write, and communicate. I say my first word before I say my second word.
But thought itself, what which often comes before we speak aloud, isn’t always so simple and temporal. Have you ever had an intuition about something? Or, an idea suddenly came to your mind? That thought doesn’t come in a token-by-token sequence—it comes in one moment.
Now, one of the reasons why I like natural language processing (and the artificial intelligence field in general) is because we can borrow ideas from one modality (say, language) and apply them to the a completely different modality (say, vision). For example, transformers were originally created for language translation tasks, but researchers found a way to apply them to predictive imaging tasks. Pretty neat, right?
However, it’s not as easy as it seems. You can’t always just take a model architecture from language and slap it onto vision; there are fundamental differences that we have to account for. For example, language is discrete (it’s made of individual words / tokens) whereas vision is continuous. Images typically have just a few output sizes that they tend to come out in, whereas the output of an LLM can span from 1 token to 65,536.
Image diffusion
Ever wonder how images are generated? It’s a little different from the language output that you get from ChatGPT. Most image generation models today use a process called diffusion. Image diffusion is a process where a model generates an image by learning how to remove noise. First, you give the model an image with a text caption. Then, you create different versions of those images with different amounts of Gaussian noise added to them. To train the model, you give the model the noisiest image, and it tries to learn how to remove the noise the correct way, using your images as the ground-truth.
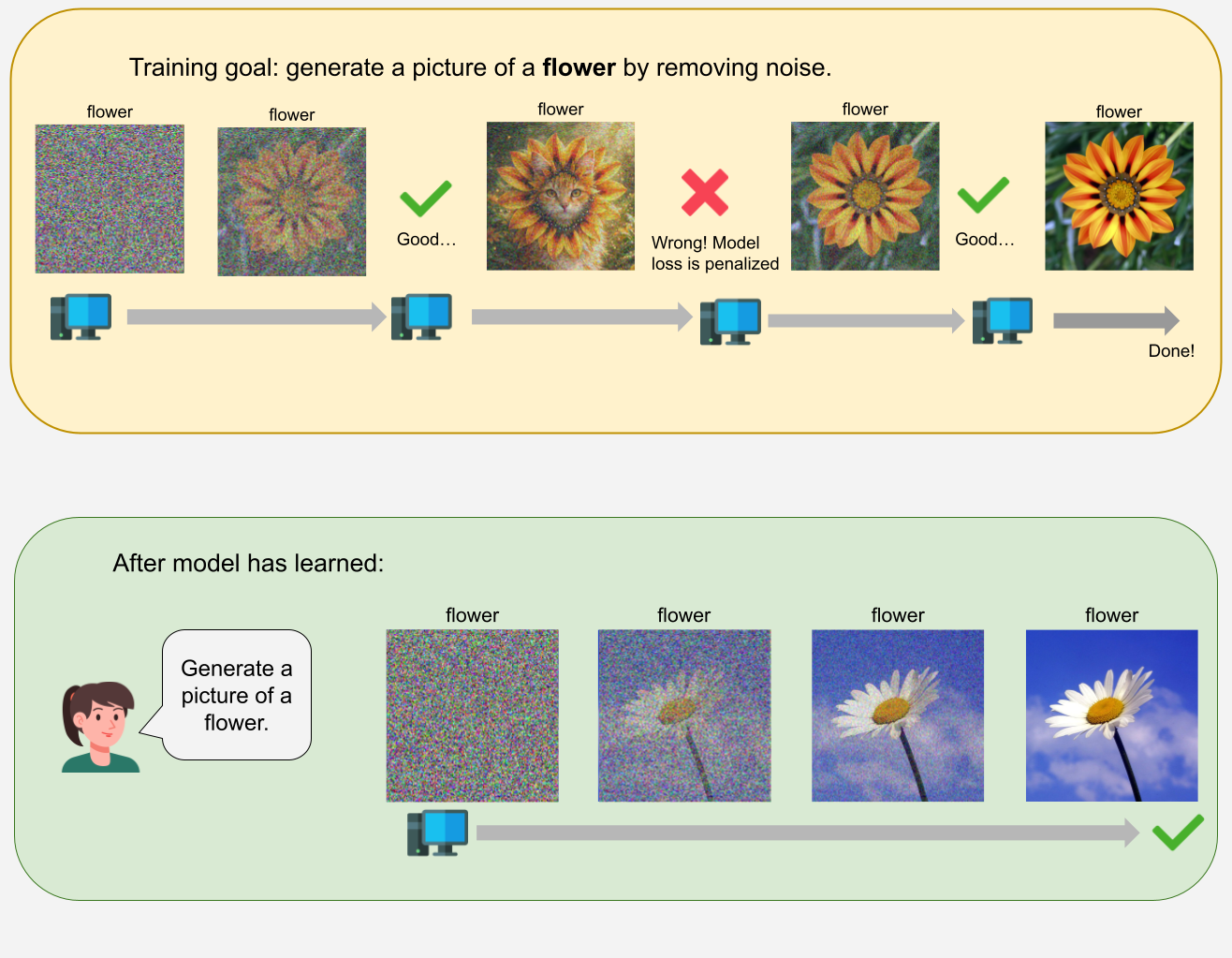
Above: The model learns how to correctly remove Gaussian noise for a specified image (flower).
Language diffusion
Diffusion images work nicely for images for certain reasons. First of all, images are a fixed size—if you want to generate an image, it’ll be 226x226 pixels most of the time. Second, images are continuous, and so the concept of adding noise to them makes sense. Would you be surprised then, if I told you that there was a diffusion model for language models? It definitely surprised me at first. Specifically, I wondered, how can we add “noise” to words?
Above: How do we add the same type of pixelated “noise” to words?
Nie and Zhu et al. answer this question in their work, Large Language Diffusion Models. The authors create a diffusion language model, LlaDa, by randomly masking individual tokens. LlaDa then generates text by predicting how to unmask the tokens. This is similar to image diffusion, where the model learns how to remove the Gaussian noise pixels—except instead of predicting which pixel lies underneath, Llada predicts which token lies underneath.

Above: Diffusion models generate text by predicting what lies underneath the masked tokens.
Looking at this graphic, you may notice that the output of the answer already had a size predetermined—8 tokens. However, we don’t always know how long we want a language model’s response to be in advance. (In fact, in my opinion, that should be for the language model to determine). To address this fixed output size issues, the creators of Llada output multiple versions of their model.
- Two of them are a more pure diffusion approach, where the output is either pre-determined by a specified amount of tokens, or is just permanently fixed. This version implements the classic diffusion, but it also has the limitation of the user needing to know how long they want their output to be.
- The other versions are a more autoregressive-style approach, where the output keeps diffusing, chunks of a time, until the model reaches an end token.
This second approach, while it doesn’t require a pre-specified output length, may undermine the benefits of a diffusion language model, where the whole point is that it is not supposed to be autoregressive. So, the short answer is: dealing with the fixed output length of diffusion models is still an active area of research!
Now, with this limitation, why do people even care about Diffusion Language Models? There are multiple reasons, specified by Li et al. First of all, diffusion models have the potential to be faster than autoregressive models, because they generate all their tokens in parallel rather than step-by-step. Second, autoregressive models can only look at tokens that they have already written - they cannot look “ahead”. Diffusion models, on the other hand, can look in all directions, potentially enabling them to capture more nuanced language understanding. These are just some of the benefits.
Diffusion for Lateral Thinking
One work that leans into fully leveraging Diffusion Language Models’ benefits is Reinforcing the Diffusion Chain of Lateral Thought (DCoLT) with Diffusion Language Models by Huang and Chen et al. The authors propose an interesting problem: Chain of Thought, while helpful for LLM reasoning, is still autoregressive in nature. It teaches models how to think each thought step-by-step, similar to how it generates individual tokens.
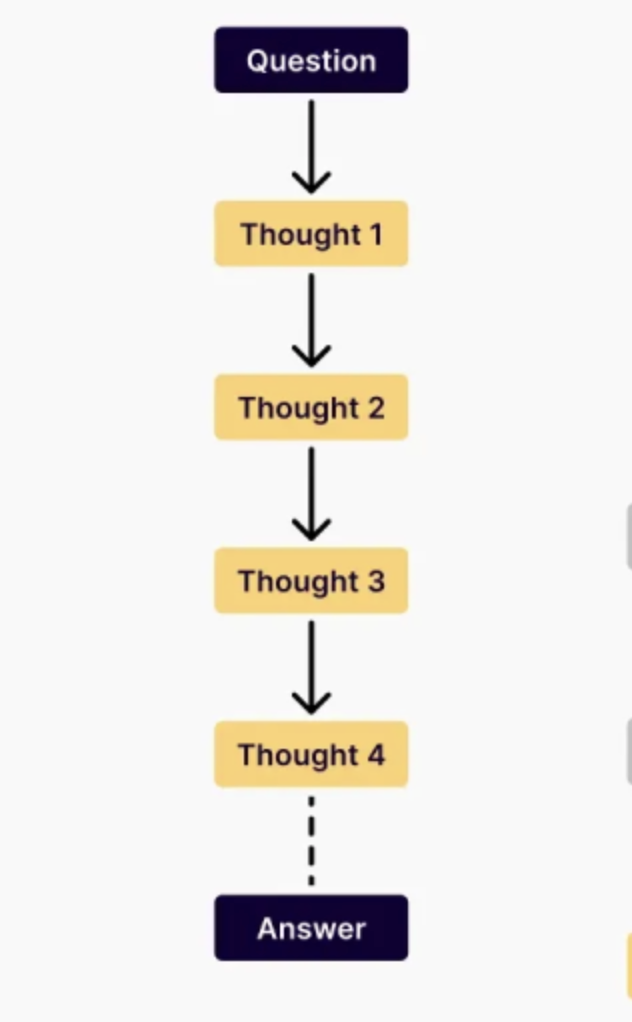
Above: Chain-of-thought (CoT) has models think step-by-step to improve reasoning results: https://www.linkedin.com/pulse/how-teach-chain-of-thought-reasoning-your-gdbzf/
However, not all thinking is done step-by-step! As I’ve mentioned before, getting a gut feeling or an idea is something that happens all at once. Furthermore, when humans are trying to answer a question creatively, they may think more “messily” and broadly, trying to think of all potential solutions before diving into solving a specific one step-by-step. Specifically, this is known as lateral thinking, a term coined by Edward de Bono.
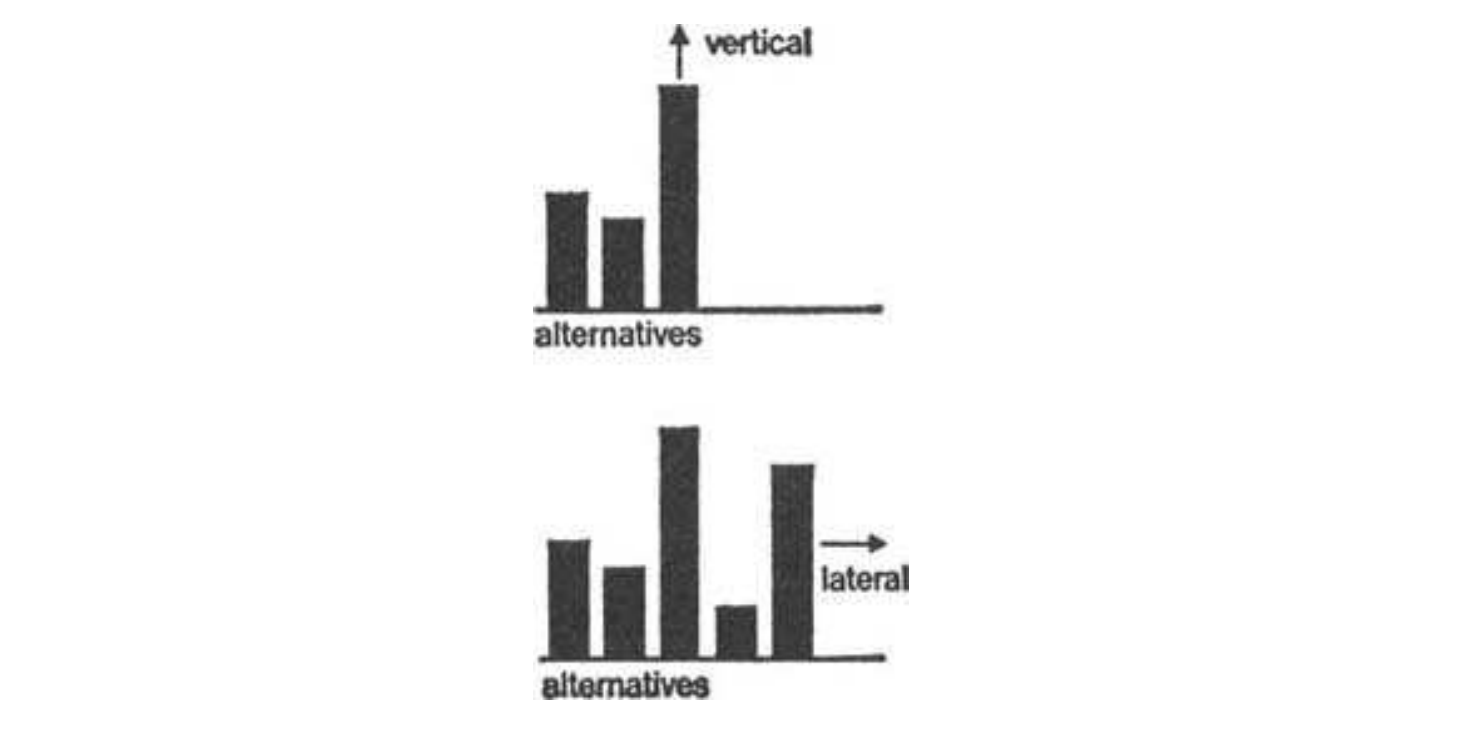
Above: Vertical vs Lateral thinking. Source: De Bono, Edward, and Efrem Zimbalist. Lateral thinking. London: Penguin, 1970.
The authors of DCoLT observes that diffusion language models provide the perfect opportunity to allow an LLM to think laterally rather than vertically (step-by-step). To do this, they fine-tune LlaDa (the diffusion language model mentioned earlier!) via Reinforcement Learning with an Unmasking Policy Module (UPM). That’s a lot of words, so let me break it down. LlaDa already learned how to unmask tokens and predict what was lying underneath. However, the tokens that were unmasked were chosen based on the highest condfidence. DCoLT takes LlaDa and builds upon it, training the model to unmask tokens not on highest confidence, but specifically on how to reason the best.
How are they able to do this? The key idea here is Reinforcement Learning (RL). RL allows you to create a custom reward function, allowing you to improve the specific task you want to focus on. The idea of using RL to improve reasoning specifically is borrowed from DeepSeek-R1. The main difference between DeepSeek’s version and DCoLT is that DeepSeek applies this method to the autoregressive, step-by-step, Chain-of-Thought reasoning, whereas the authors of DCoLT take on the diffusion approach.
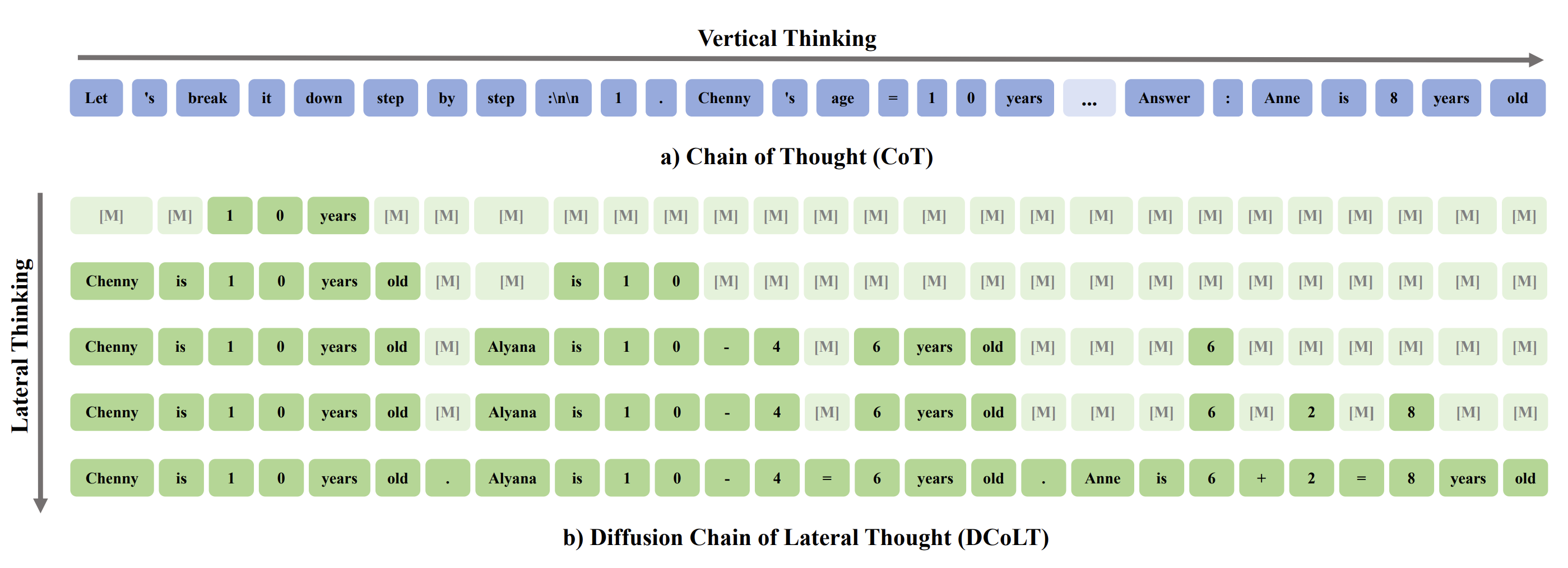
Above: The Diffusion Chain of Lateral Thought process. Entire thoughts are generated in parallel, rather than one thought after another.
Conclusion and Takeaways
Let’s zoom back out for a summary, because this blog post was quite the journey. Here are the key points to take away:
- Most LLMs are autoregressive, meaning they generate text token-by-token. Diffusion, on the other hand, generates objects all at once by learning to remove noise.
- Diffusion is a popular method for image generation: the model learns how to remove pixelated noise to generate an image based on a text descriptor.
- Nie and Zhu et al., the creators of LlaDa, creatively apply diffusion to LLMs by randomly masking individual tokens.
- On another note, DeepSeek-R1 discovered that using Reinforcement Learning is a useful tool to improve model reasoning. However, this was still from an autoregressive, step-by-step, thought-by-thought perspective.
- Huang and Chen et al., DCoLT authors, combine language diffusion (LlaDA) with DeepSeek-R1’s technique to improve reasoning through Reinforcement Learning. They build a language diffusion model, specifically for reasoning, that mimics lateral thinking over vertical, step-by-step thinking.
Overall, I find the language diffusion space interesting for multiple reasons. First, I love how diffusion was a method that was originally used for image generation, but then was applied to language generation. I also agree with the authors of DCoLT that using only CoT examples to improve reasoning can be a limitation; when I think about how we as humans think, it is definitely not always step-by-step. However, there are other researchers who have realized that human thinking is not always linear. Works like Tree of Thoughts and Graph of Thoughts implement alternate thinking approaches that are also not only step-by-step.
In general, it will be exciting to see where diffusion models take us in the future, and how they will grow compared to their currently popular autoregressive counterparts. I believe they are definitely an interesting type of language model that have a large number of untapped benefits.