
LINC: Neurosymbolic Reasoning for LLMs
Published:
This post is an overview of the paper: LINC: A Neurosymbolic Approach for Logical Reasoning by Combining Language Models with First-Order Logic Provers by Olausson et al. The paper is linked here: https://arxiv.org/pdf/2310.15164
Introduction
In today’s world, as people rely more and more on chatbots, logical reasoning is an extremely important task for LLMs. In the legal and medical domains, for example, it is imperative that we can verify the correctness and validity of LLMs’ claims. However, if you have ever used a chatbot, you may know that LLMs can be wrong sometimes. Why does this happen? From a very high-level viewpoint, this is because pure LLMs are “next likely token predictors”. They simply predict what the next likely word is based on what they have seen in training data. As a result, when we analyze their outputs from a human perspective, we find flaws, incorrect reasoning statements, and hallucinations (aka, something the model completely ‘made up’).
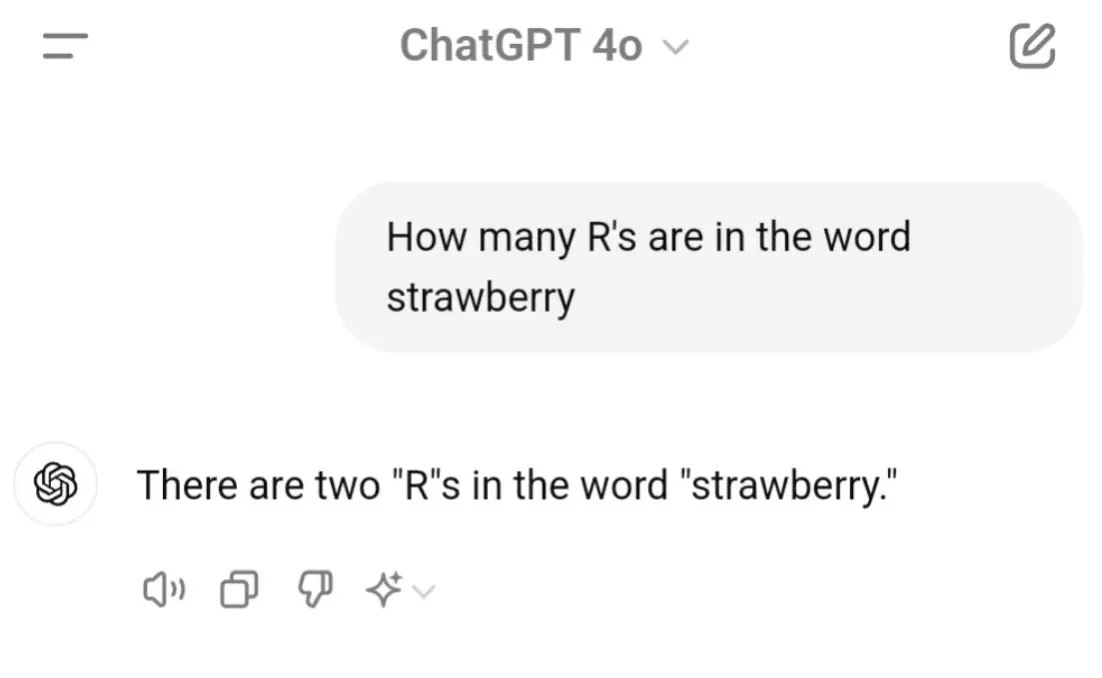
Above: A famous case of older versions of ChatGPT failing to properly count how many r’s are in the word strawberry
Chain of Thought
One groundbreaking method to improve LLM reasoning was the 2022 Chain-of-Thought approach (CoT) by Wei et al. In short, the way CoT works is that it has the model “think out loud” before generating a final response. The researchers found that this prompt-based approach significantly improved LLM reasoning performances on a wide range of tasks.
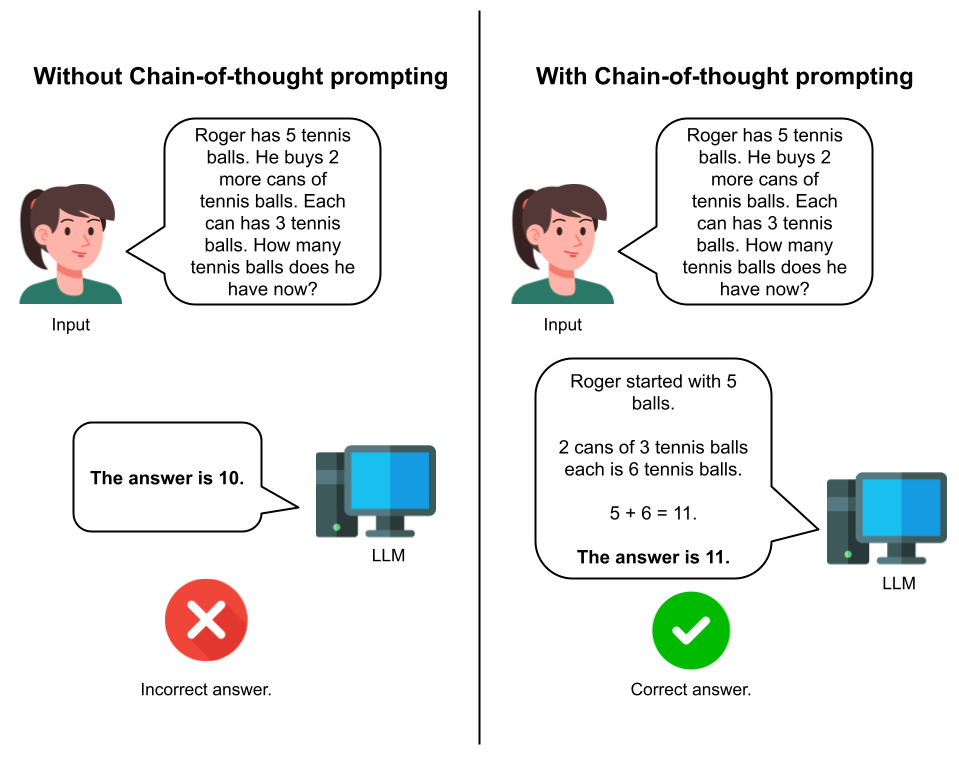
CoT is a brilliant approach that significantly improves LLM reasoning performance on arithmetic, commonsense, and logical reasoning tasks. However, when I hear about prompt-based approaches, I wonder if there is another side that we are missing altogether. Prompt-based approaches still rely on the “next likely token” text generation. Specifically, when it comes to logical reasoning, there are many formal rules that we could leverage to help the model reason, rather than simply relying on a (at certain times, somewhat flimsy) probabilistic word generation approach.

Above: Many day-to-day reasoning tasks in natural language can be translated to formal logical representations.
LINC Overview
This is exactly where Logical Inference via Neurosymbolic Computation (LINC) comes in. The authors behind LINC agree that prompt-based approaches (like CoT) and increasing the model size can help improve LLM reasoning performance, however, there are still limitations. The authors decide to leverage the formal rules of logic in their method, making it a neurosymbolic approach, described below.
First, the model converts the natural language (NL) expression into a First-order-logic (FOL) expression. Essentially, it converts the regular text into logic symbols.
Next, they use a symbolic FOL solver, that specifically relies on logic rules, to determine the truth value of the conclusion. There can be three possible outputs: True, False, or Uncertain (e.g. if there was not enough information to solve the problem).
Finally, they run this process K times and decide on the answer that appears the majority of the time. (This reminds me of an agentic-style approach!)
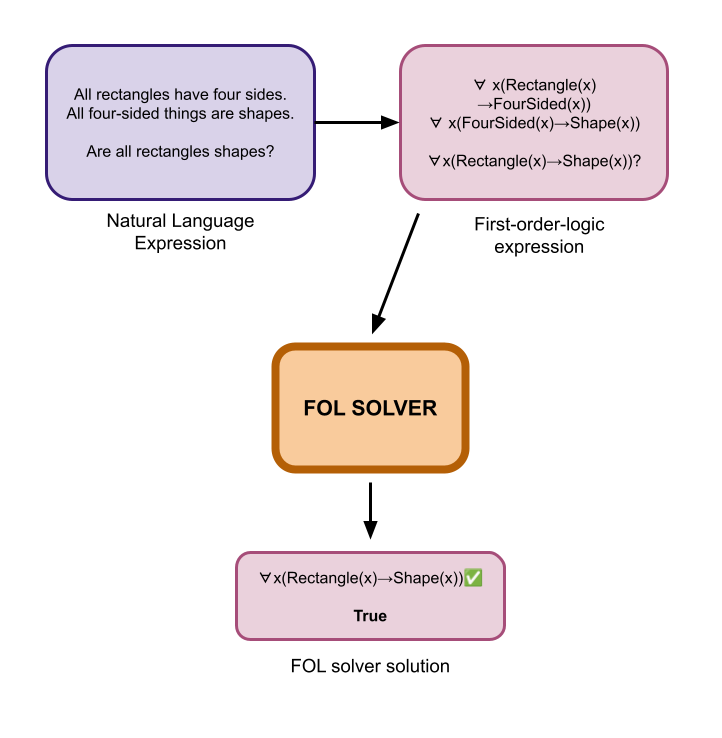
Above: LINC first converts the natural language expression to a logical one, then uses a logic solver to solve it.
LINC Results and Analysis
The authors test LINC on three different pre-trained LLMs and two different evaluation datasets. They find that LINC has better performance results than almost all of the other methods. What is potentially more interesting to analyze, however, is how LINC fails — compared to how CoT fails.
In short, with LINC, the issues arise when converting the natural language into the symbolic representation. For example, the authors find that LINC may not capture implicit commonsense information that could affect the premises. In the example below, the model derives a solution of “Uncertain” because it was not able to make the implicit assumption that Harry is a person.

There is also the issue of multiple representations. LINC struggles when it is given a lot of information about one object because it is unable to decide if this information is independent from each other or not. Additionally, certain words may have multiple meanings, causing syntax errors in the logical expression when terms are seemingly repeated. CoT, on the other hand, does not tend to fail at these tasks.
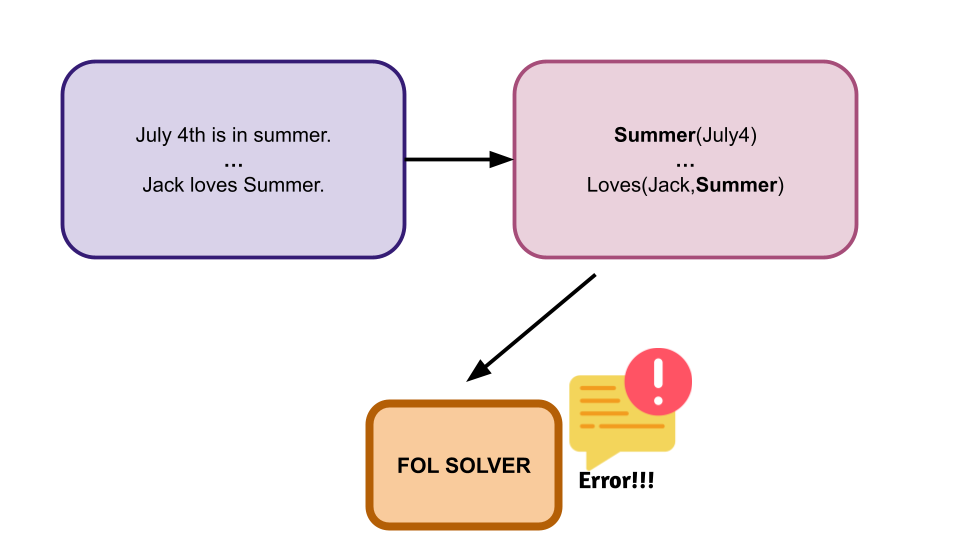
Above: Language ambiguity can cause syntax errors in the FOL expression or cause issues for the solver.
However, CoT has different issues. First of all, sometimes CoT will reason about something correctly, but ultimately decide on a different answer in the very last moment. Second, CoT will simply just not follow logical rules sometimes - completely the opposite of the FOL solver. Finally, CoT fails with more complex, longer reasoning tasks. This illustrates the strengths and weaknesses of the two approaches: CoT is more language-based while LINC is more rule-based, and their performances reflect this.
Thoughts and takeaways
I thought this paper was super interesting. The failure analysis of LINC shows that most of the challenge for LLM reasoning comes from, well, the language part. This makes sense, because if we start from a perfect formal symbolic representation of a statement, we should theoretically also perfectly be able to solve it, since logical reasoning follows set rules (like a math problem). The challenge of LLM reasoning comes from actually translating the language statement into the formal symbolic representation.
Connecting to schoolwork
I find several connections in the challenges mentioned in this LINC paper and traditional NLP challenges discussed in my NLP class this semester. For example, the ambiguity of language is what makes NLP so challenging. Additionally, the challenge that the FOL symbols have with repeated terms - treating them as the same entity rather than unique ones - reminds me of co-reference resolution.
Optimizing the FOL Solver
LINC uses a fixed symbolic solver. However, this work from Liu and Fu et al. mentions that while earlier neurosymbolic methods used a fixed external logical reasoning engine, one could potentially also optimize the reasoning engine. Optimizing the reasoning engine could be an interesting area of future work.
Conclusion
Overall, while the failure cases of LINC are interesting to learn from, it’s important to emphasize that LINC is an impressive and successful approach that demonstrated improvements across almost all LLM reasoning benchmarks, including CoT. It goes to show that indeed, the neurosymbolic approach is a promising direction for LLM reasoning and verifying the validity of what an LLM “says”.