
Dissociating Language and Thought in LLMs
Published:
This post is an overview of the paper: Dissociating Language and Thought in Large Language Models: A Cognitive Perspective by Mahowald and Ivanova et al. The paper is linked here: https://arxiv.org/abs/2301.06627
Separation of language and thought
In my introductory linguistics course, one of the first concepts we learned about was the separation of language and intelligence. Specifically, we learned that just because someone seems to be a ‘good’ speaker does not automatically make them intelligent, and vice versa; just because someone is not so great at speaking does not mean they are not intelligent. Regardless, we as humans still have a bias. If we hear someone speaking well, we may assume they are intelligent and skilled in other unrelated areas, even without meaning to.
When it comes to machine language, humans are not immune to having the same biases. This is because “[w]hen we hear a sentence, we typically assume that it was produced by a rational, thinking agent (another person)” Mahowald, Ivanova et al. For over 100,000 years, the only entities who could converse in human language, were, well, humans. This explains why humans trust LLMs (even when they hallucinate), feel connected to them, and sometimes even feel that they are sentient.

The authors continue to say that because LLMs are so good at certain language tasks, such as text comprehension and next-word prediction, people get these advanced language skills conflated with Artificial General Intelligence. This blending of language and thought is further reinforced by the influence of the Turing Test of 1949. The Turing Test says that if a human is unable to decipher text between another human and a machine, then this machine could be said to be intelligent.
However, intelligence goes beyond how well someone, or some machine, can speak. The authors say that due to “the fact that language can, and typically does, reflect underlying thoughts”, people have misconceptions when it comes to the way language and thought are connected. Just because someone is good at language, does not mean that they are good at thinking. From my previous posts and LLM reasoning performances alone, it is quite intuitive why this is a fallacy.
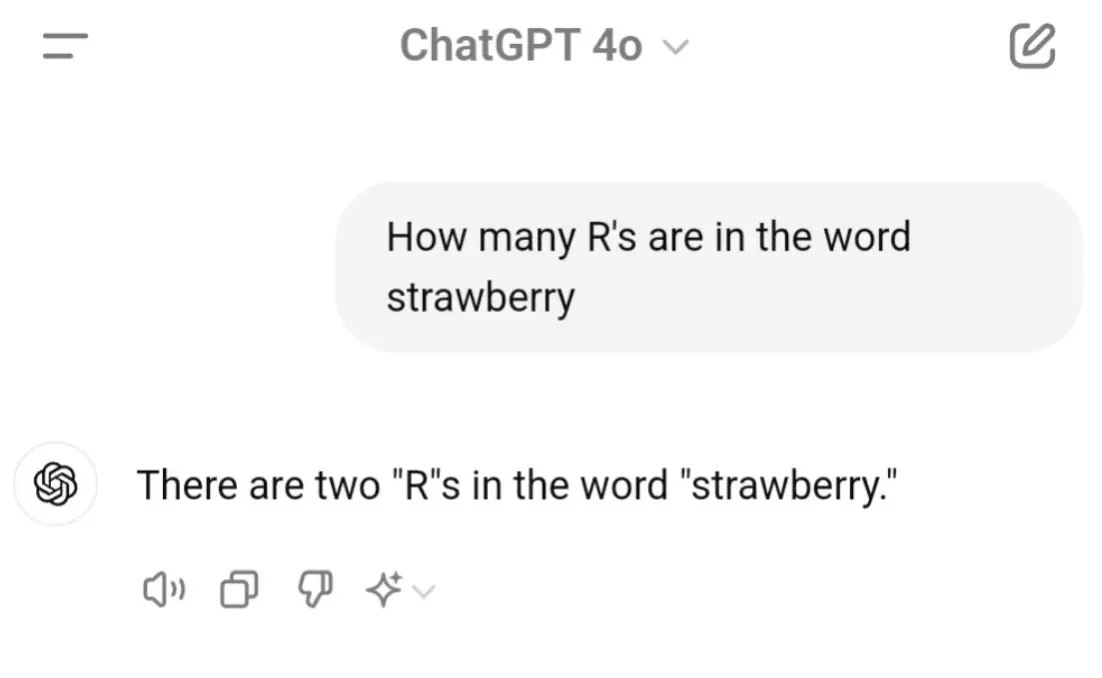
Above: A famous case of older versions of ChatGPT failing to properly count how many r’s are in the word strawberry
In the above image, though the model is great at ‘speaking’, its answer is incorrect, showing that it is bad at ‘thinking’, ultimately disproving the idea that “good at language” always implies “good at thought” in LLMs (and this is true for humans, too!).
In the human brain, there has been evidence that language and thought are detachable. With this motivation, the authors present two different kinds of linguistic competence that LLMs could be evaluated on. The first one is formal linguistic competence, which deals with how good an LLM is at knowing the rules and statistical laws of language. Formal linguistic competence is more connected to ‘speaking’ and following correct grammar rules.
The second one is functional linguistic competence, which deals with an LLM’s ability to use language “in the real world”, often relying on non-linguistic skills. Functional linguistic competence is more connected to ‘thinking’, such as reasoning about diverse topics, making requests, and overall, interfacing with other cognitive components and ultimately, other entities.
With this new framework in mind, the authors argue that modern LLMs can be great at formal language but are not so great at modeling human thought.
Formal linguistic competence
First, the authors discuss how LLMs are pretty good at formal linguistic competence. Modern transformer models (this paper was published in 2023, so they mainly discuss GPT-3) are coherent, great at generating text, performing specific tasks with simple prompting, and overall, excellent at grammar. They can even predict next words for humans which matches human neural behavior.
However, some limitations are that LLMs can over-rely on statistical rules when it comes to language. Furthermore, something that I thought was really interesting was that LLMs see 100-1000 times as much data as a child is exposed to. This goes to show that even if LLMs are learning the rules of language from statistical rules, these current methods lack something that humans have when it comes to learning language. At the time that this paper was written, I don’t think small language models had taken off yet, but today, there is a wide variety of small language models (Llama3.2-1B, SmolLM2-1.7B, etc.), which shows promise for language models that can also learn on smaller datasets.

Functional linguistic competence
Next, the authors discuss how LLMs are weaker when it comes to functional linguistic competence (the ‘thinking’ part). Since natural language contains factual knowledge, LLMs trained on a lot of text must acquire some factual knowledge. This often comes from word co-occurrence patterns (co-occurrence relates to which words show up frequently together). For example, during training, if “Austin” shows up frequently next to “The capital of Texas is…”, then the LLM will ‘learn’ that Austin is the capital of Texas just from the text alone.

Hence, the authors claim that “any test of LLMs’ ability to reason must account for their ability to use word co-occurrence patterns to “hack” the task.”
Now, this statement conflicts me. I agree, that when I first truly understood how LLMs were trained, it definitely felt like an LLM knowing something only because it was good at predicting a next token felt like ‘hacking’. On the other hand, even if an LLM is simply a next-likely-token predictor, we cannot discount when they get things right or are ‘good’ at certain tasks, even if that learning was done through word frequency relations. Modern methods also use external methods like Retrieval-Augmented Generation or external solvers (LINC, Faithful CoT) to mitigate this issue. Still, an over-reliance on statistical patterns can lead to issues like the Reversal Curse!
In the rest of the section, the authors discuss more limitations of LLMs compared to humans, including:
- Formal reasoning: LLMs’ tend to do worse on reasoning tasks when the task is not something that one would see in the typical dataset (called ‘out of distribution’ data). For example, with unusual tasks such as “Get your sofa onto the roof of your house without using a pulley”, humans tend to do much better than LLMs, even though the reasoning behind it is not necessarily complex.
- World knowledge & commonsense: LLMs’ general knowledge is biased: On the internet, humans tend to write about things that are unusual or noteworthy, and less so about implied common facts. As a result, LLMs may struggle with underreported knowledge such as the fact that wheels tend to be round.
- Situation modeling: LLMs are incapable of tracking information over long conversations, unlike humans, who can have a three-hour long conversation and still remember most ofit the next day. (Note: this was true at the time of writing, but LLMs since then have seen tremendous growth in context windows, for example, with Gemini Pro having a context window of over a million tokens.)
- Pragmatics and intent: LLMs struggle to understand users’ intent, sarcasm, and jokes. I found that since the writing of this paper, LLMs’ ability to understand sarcasm has improved, but is still not at the level of humans (Bojić et al).
Conclusion
Overall, due to LLMs’ limitations in formal reasoning, world knowledge, situation modeling, and social reasoning (e.g. sarcasm), the authors argue that LLMs are weak in functional linguistic competence. This highlights the fact that just because a system is good at language does not imply it is good at thought.
Now this is the most fundamental argument; language and thought are separate systems, and perhaps trying to model both with just one LLM system is not practical. The authors argue that, similar to the human brain, a truly intelligent model must not only have a language processor, but a problem solver component, an experiencer component, a situation modeler, a reasoning component, and a goal decider. They tie it back into the Turing Test: “a model that masters language use, not just the rules and patterns of natural language, has to be a general intelligence model.“
Therefore, there should be separate benchmarks for LLMs: some for formal linguistic competence (which already exist), and some for functional linguistic competence.

Thoughts and takeaways
I thought this article was really well-written. It really reinforced the fact that pure, traditional LLMs are next-token predictors rather than agents with intent or goals. When you engage in a conversation with a chatbot, it may feel like you are talking to someone, but in reality, you are not actually talking to anyone. This sense of perceived agency is what makes talking to one so misleading.
Overall, I agree with the general sentiment that some “language use” tasks are better when offloaded to a non-LLM or an external solver, such as LINC or utilizing Retrieval-Augmented Generation. On the other hand, after reading this article, using word co-occurrence patterns to learn facts doesn’t honestly feel that much like hacking to me. Yes, it may not be as grounded as other methods, but ‘learning’ that Austin is the capital of Texas because you’ve seen “The capital of Texas is Austin” written in so many internet documents still feels like a valid way to learn something if it works for the most part. However, this shouldn’t be everything: we don’t want models to be right ‘most of the time’, we want them to be right ‘all of the time’.
I also wonder if the categories mentioned — problem solver, experiencer, situation modeler, etc. — are the meant to be a definitive characterization of an intelligent agent, or just one helpful framework along with many others. I agree that intelligence goes beyond just how well someone speaks, but I also know that the definition of it is highly debated, and so I wonder what other models or frameworks one could follow to create such an intelligent agent. Perhaps we don’t have to model intelligence after the human brain at all. If language models can learn how to ‘speak’ (at least, in terms of formal linguistic competence) differently than humans do, perhaps we can create intelligent agents using a non-human framework too.