
Faithful Chain-of-Thought Reasoning
Published:
This post is an overview of the paper: Faithful Chain-of-Thought Reasoning by Lyu, Havaldar, Stein et al. The paper is linked here: https://arxiv.org/pdf/2310.15164
Introduction
Today, if you ask a chatbot a math question or a complex reasoning question, it will likely provide the correct answer. There was a time, however, where this level of performance was unimaginable. This is because while LLMs are good at imitating surface-level human language, the structured reasoning beneath the language — reasoning that humans usually find quite simple — is a fundamentally different problem. Creating models that can properly think and reason rather than simply “talk” is a largely unsolved challenge in AI.
Background: Original Chain-of-Thought (and some limitations)
One method that drastically advanced reasoning capabilities of LLMs was Chain of Thought (CoT). CoT, published in 2022, was a prompting strategy that led to groundbreaking improvements in LLMs’ reasoning capabilities on complex reasoning tasks, like math and commonsense. The way CoT works is fairly simple: just ask the model to “show its work”. More specifically, instead of asking an LLM a direct question, you provide several examples of “showing your thinking”. Then, in its response, the LLM also will “show its thinking”, leading to more accurate responses.

Above: The input prompts the model to “show its thinking” by placing a reasoning example in the demo question-answer pair.
CoT led to striking improvements in LLM reasoning performances on several benchmarks. That wasn’t its only benefit, however. A second benefit was that CoT provided an interpretable window into how the LLM was “thinking”. Since CoT forces the model to “show its work”, one can see exactly which steps the LLM took to reason in its final answer. This can be useful for tracing errors and boosting explainability.
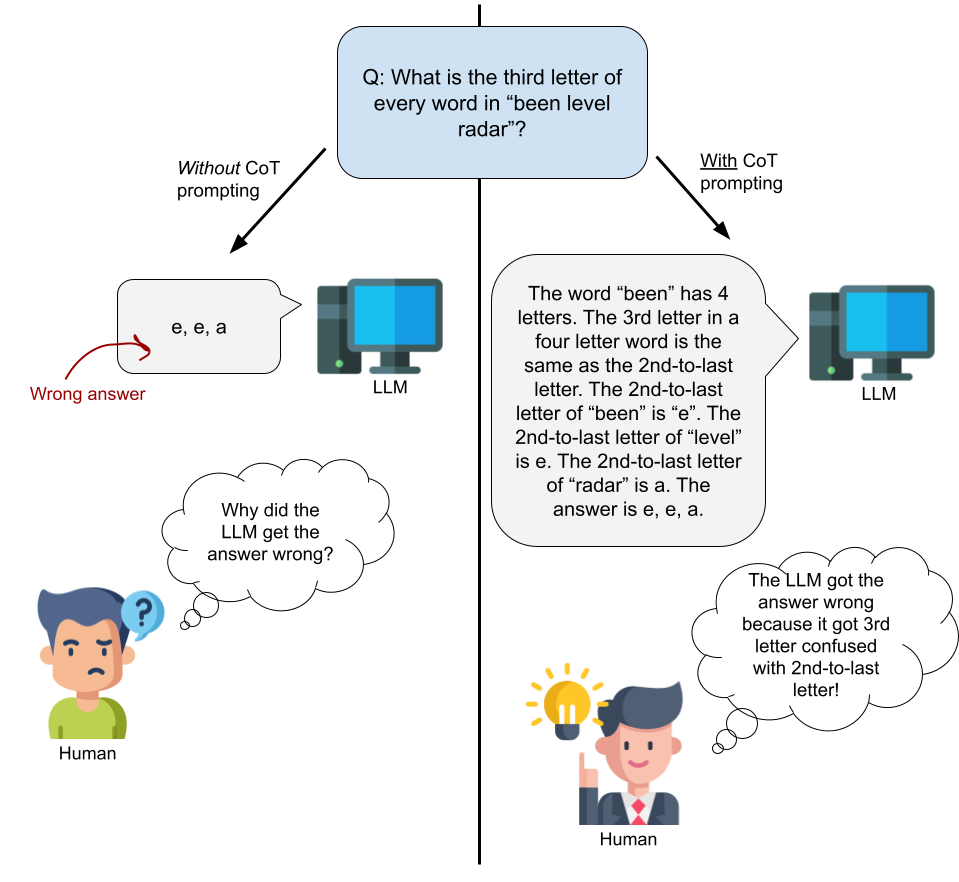
Above: When an LLM is prompted with CoT, it “shows its thinking”, which can be useful when trying to understand why it got an answer wrong.
However, this is not always reliable. One issue with CoT is that it is not always faithful to its reasoning process. Faithfulness refers to if the outputted reasoning text actually reflects the process that the model took to get to that answer. Below is an example of reasoning steps of CoT not being faithful.

Above: The LLM uses CoT to explain its work and arrives at an answer of $200 in the reasoning chain. However, in the last moment, for some reason, it randomly switches and says the final answer is $0.
In the above image, though the reasoning process looks plausible, the final output of the LLM completely contradicts the reasoning steps. This means that the model may not have actually taken those reasoning steps to reach its final answer. The reasoning steps also do not explain why the LLM randomly switched its answer in the last moment. Unfaithfulness in LLM reasoning can be misleading and even dangerous in higher stakes fields where explainability and error understanding are crucial.
Faithful Chain-of-Thought
To solve this issue, the authors present Faithful Chain-of-Thought. They break down complex reasoning tasks into 2 stages: Translation and Problem Solving.
Translation
In translation, the language model translates the given question into a reasoning chain. Unlike plain CoT, which uses only natural language (e.g. plain English) in its reasoning chain, this new reasoning chain is a combination of natural language and symbolic language (like code). The symbolic language chosen is dependent on the type of question. For example, Python may be used for math problems whereas Planning Domain Definition Language (PDDL) may be used for planning questions.

Problem Solving
In problem solving, the reasoning chain is executed; in the example above, the Python code would run. The output from the reasoning chain (code) is then taken as the answer itself. This component is also called a “solver”.
Conclusion
In summary, plain CoT has the LLM simply “say” what it’s thinking out loud, whereas Faithful CoT has the LLM formally execute some type of code to retrieve the final answer. In plain CoT, though the reasoning chain may look legitimate, there is no way to verify if this is what the LLM was actually “thinking”. On the other hand, with Faithful CoT, the LLM’s output is guaranteed to reflect the steps it took (or, in this case, code it ran) to reach the answer. In other words, the reasoning steps the LLM takes are faithfully tied to the final answer. This creates a more reliable explanation of the reasoning process. Faithful CoT also outperforms the orignal CoT on several reasoning benchmarks.
Now, of course, the Faithful CoT method does not ensure that the LLM always provides the perfectly correct reasoning chain. It just ensures that, for whichever reasoning chain the LLM provides, the final answer actually comes from that reasoning chain. Another direction of research is to work on the Translation component of Faithful CoT, and improve the reasoning chain that the LLM creates (“reason about reasoning”? We could get into some deep recursion here).
Thoughts and takeaways
I see similarities between Faithful CoT and LINC: Both convert a natural language question into an external type of language—either code or a planning language, or in LINC’s case, First-Order-Logic—and then use an external solver to solve the question. With Faithful CoT, I like how the type of language used is task-dependent. This intuitively feels beneficial for performance. Overall, I see a common theme of offloading the reasoning components to external solvers when improving reasoning for LLMs.
Questions to think about:
- I wonder how Faithful CoT and LINC can be applied to problems that require long reasoning chains and a lot of memory, which can be more challenging for LLMs. The reasoning questions shown here seem to be more short and simple, from my understanding.
- Both of these methods require an LLM to translate from natural language into a more symbolic one. While these methods improve performance on reasoning benchmarks, are we actually solving the problem, or are we just shifting it to a different one (translation)? And, does it really matter, if the benchmarks are being improved upon?