
Reinforcement learning for NLP
Published:
In my last post, I talked about applying an originally image-based machine learning method to language, and the challenges that came with it. Today, we’re going to be discussing a similar topic—specifically, Reinforcement Learning (RL) for NLP reasoning. Though not initially used for LLMs, RL has a number of benefits when applied to LLMs. Specifically, RL allows LLMs to learn how to create outputs with specific goals in mind.
Background
Traditionally, RL was not used for language, but rather applications like games, robotics, and general planning. The main thing to understand is that RL teaches an agent a policy in order to maximize a reward. For example, suppose we are trying to train a robot how to navigate in a square grid in order to maximize its score:
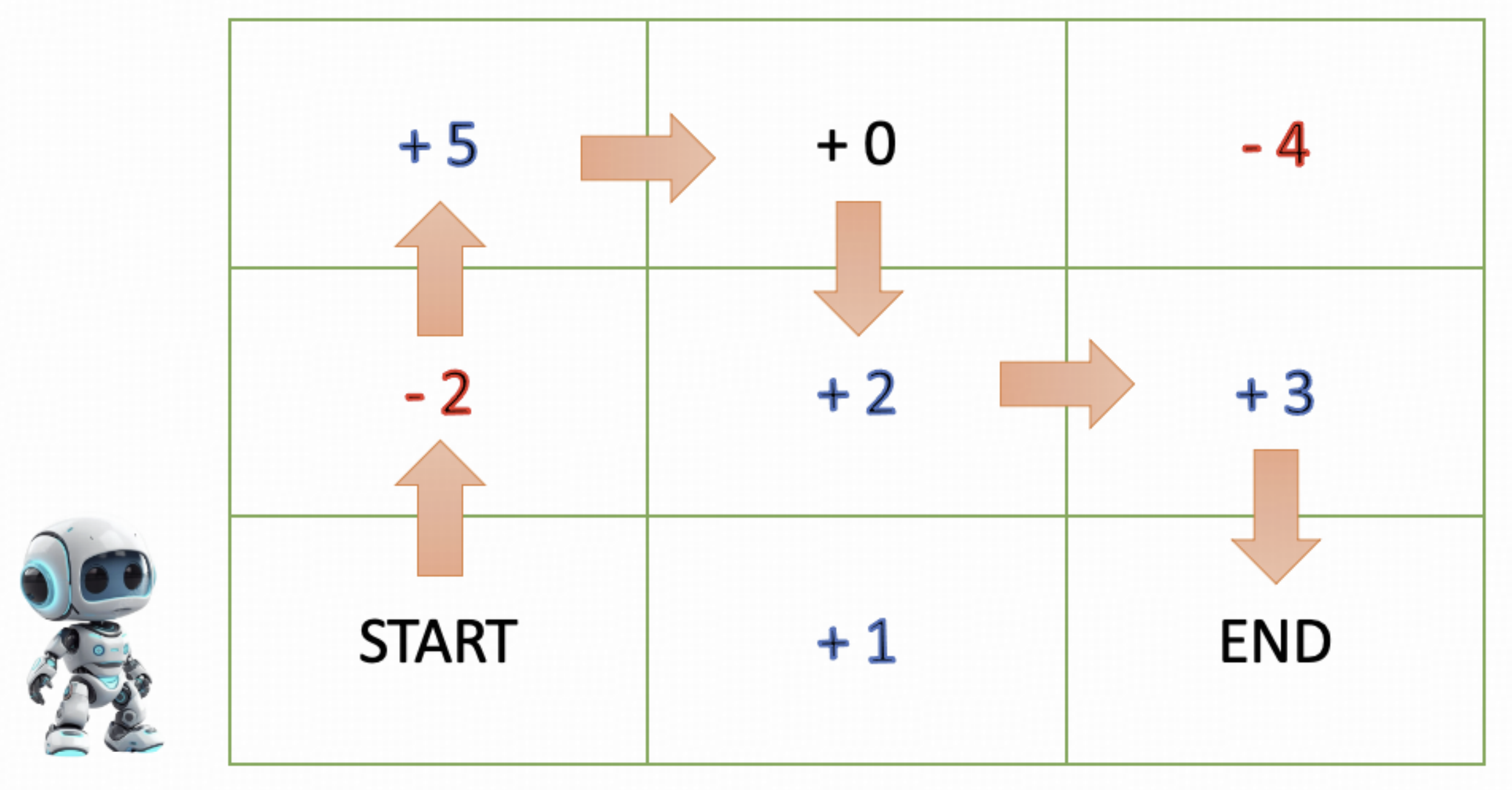
Image source: Wang et al
Suppose that the number on each square contributes to the robot’s score. Then, naturally, the robot will then be penalized for stepping on a low-number square, and rewarded for stepping on a high-number square. Through these rewards, the RL algorithm trains the robot to navigate from one end of the grid to the other in order to maximize its score (Wang et al).
Application to LLMs
Now, you may be wondering how something like this could ever relate to, say, a chatbot answering human questions. The translation is quite simple: rather than having a robot be rewarded when it steps on a high-numbered square, we can have the chatbot be rewarded when it provides a good response, and be penalized when it provides a bad response.
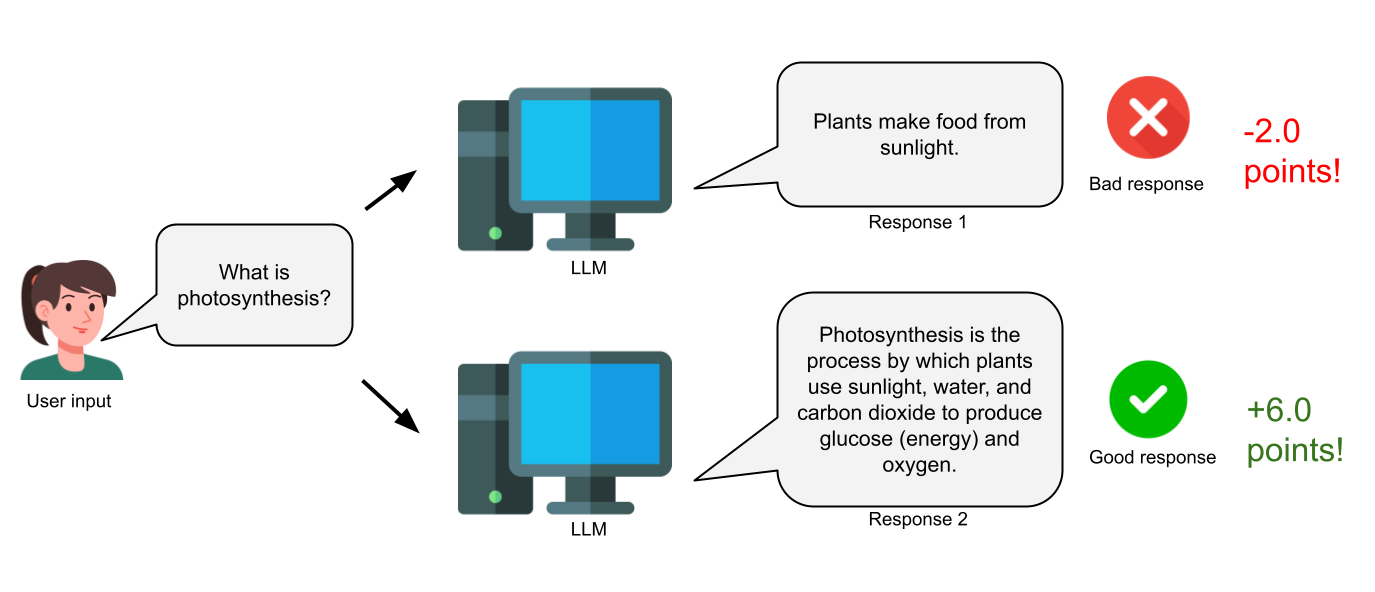
Above: Reinforcement learning (RL) for LLMs rewards them for good responses and penalizes them for bad responses.
Let’s take a step back and think about how this is different from other types of machine learning pipelines. The most well-known pipeline for LLMs is probably supervised learning, which uses explicit, labelled word data to have the model directly learn what the best next-likely-token is. While this type of data is difficult to construct, it allows the model to have a rich reference point to learn from.
On the opposite end of the spectrum is unsupervised learning, which has no labelled output data: these techniques are just used to discover existing structures and patterns in the data. Unsupervised learning does not require the human labor of constructing good output data; however, it cannot really be used to train chatbots.
RL lies in the middle of unsupervised and supervised learning, giving us the best of both worlds. Unlike supervised learning, RL does not require wordy, explicitly labelled outputs; instead, it learns from less complex reward signals (e.g. ‘good’ and ‘bad’). However, unlike unsupervised learning, we can actually use RL to train a chatbot on what to say.
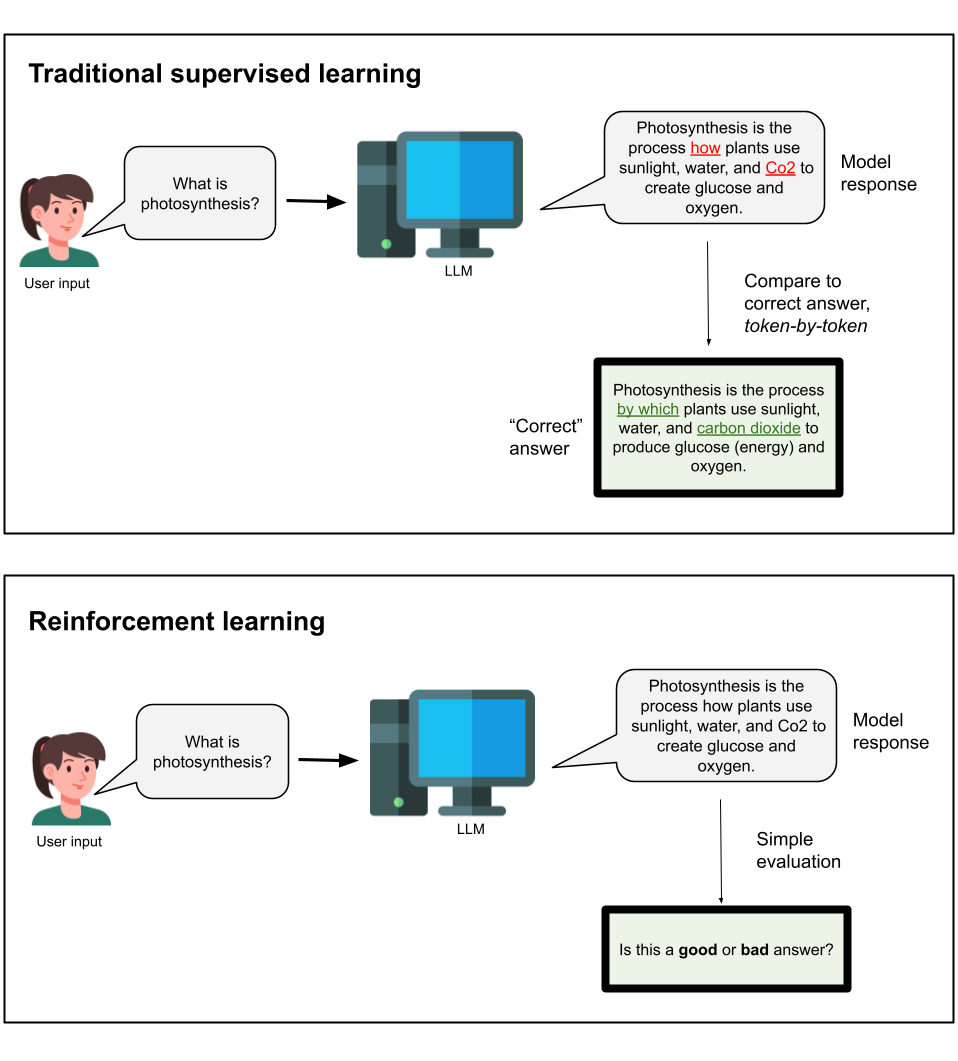
Above: RL uses simple rewards rather than trying to learn a token structure directly.
Now, RL is not the magic solution for everything. As labor-intense as gathering labelled data is, supervised learning is still necessary for the pre-training of a language model. One cannot teach a model how to speak from reward signals like ‘good’ vs ‘bad’ alone (think of if you tried to teach a human to speak in that way!). However, RL can be used in the fine-tuning stage of training an LLM, which occurs after the base step of pre-training to polish the final model, as an alternative to the traditional supervised fine-tuning.
Now, RL has more benefits beyond its simpler output label structure. One of the main benefits of RL is that it allows you to train the model with a specific goal in mind. For example, why do the rewards just have to be ‘good’ or ‘bad’? They can also be ‘safe’ or ‘unsafe’, ‘helpful’ or ‘not helpful’, ‘correct’ or ‘incorrect’. This leads us to how RL can specifically be used to improve reasoning capabilities in LLMs.
Using RL to improve reasoning in DeepSeek-R1
Chain-of-Thought prompting (Wei et al) led to amazing reasoning improvements in LLMs by simply having the model ‘think step-by-step’ in its answer. With this in mind, researchers at Google decided to go beyond prompting, and try to actually train an LLM on these step-by-step reasoning trajectories. As expected, this training improved the reasoning capabilities of models on several benchmarks (Chung, Hou, Longpre et al).
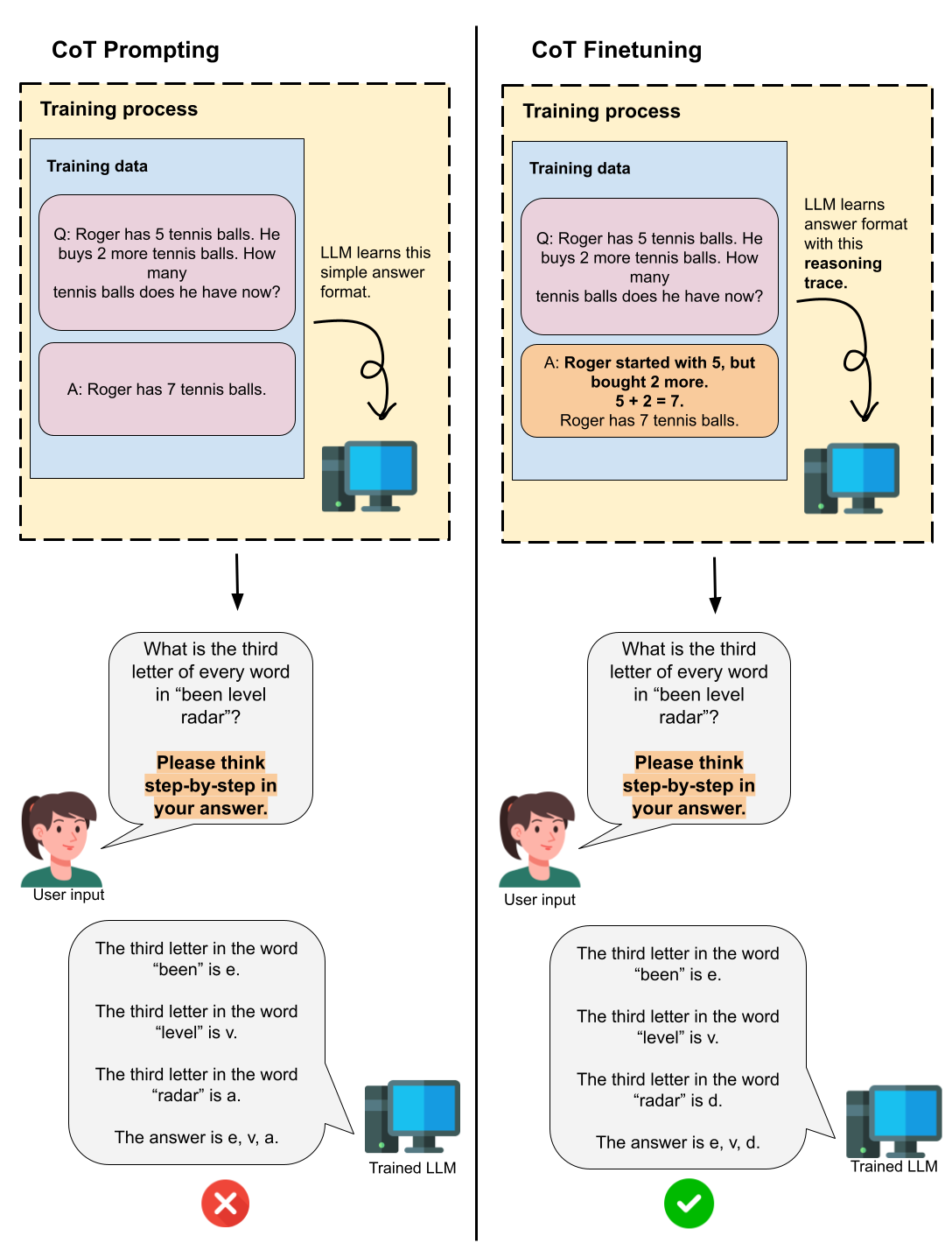
Above: CoT prompting only has the model ‘think out loud’ after it’s done training, while CoT finetuning actually trains the model on thinking out loud.
However, while training on reasoning traces improves performance, the authors of Deepseek-R1 argue that gathering these human-labelled reasoning trajectories is expensive. More importantly, these human-labelled reasoning traces were created by, well, humans. An LLM could potentially think differently (maybe even better) than a human does. Why does it have to copy this limited, human-based reasoning process?
To explore this question, the Deepseek-R1 authors use RL to train their LLM. Remember how we said that RL allows you to have different reward types? In this case, rather than giving a ‘good’ or ‘bad’ reward, the authors give a ‘correct’ vs ‘incorrect’ reward. Addtionally, they have the model output some sort of reasoning trace, but they only reward and penalize the model’s final answer. That means that there is no influence on the reasoning process that the model comes up with. As a result, the model can potentially learn non-human reasoning pathways while still learning how to reach a correct final answer!
Something interesting happened when doing this: the original model had great reasoning capabilities, however, its reasoning traces had very poor readability and were occasionally mixing English and Chinese. To improve readability of reasoning traces, the authors suppressed this language mixing behavior in the final model.
Initially, when reading this, my intuition told me that suppressing the language mixing was maybe not the most beneficial for the model’s reasoning. If the whole point of using RL was to have the model create the best, non-human-influenced, reasoning traces, and it naturally developed language mixing, then why get rid of that? Indeed, as specified in the paper: suppressing language mixing in Deepseek-R1-0 did actually decrease reasoning capabilities.
In fact, Li et al studied this more directly and found that language mixing is not a random artifact of these RL-created reasoning traces, but rather, a deliberate and strategic reasoning choice that tends to help reasoning performance in LLMs. It’s exciting how although using RL in Deepseek was initially only to improve model reasoning capabilities, an unexpected byproduct was the finding of this tool that improves LLM problem-solving ability.
‘I don’t know’ in Language Models
What actually inspired me to start this post about RL for LLMs was this tweet and subsequent comment I saw the other day.
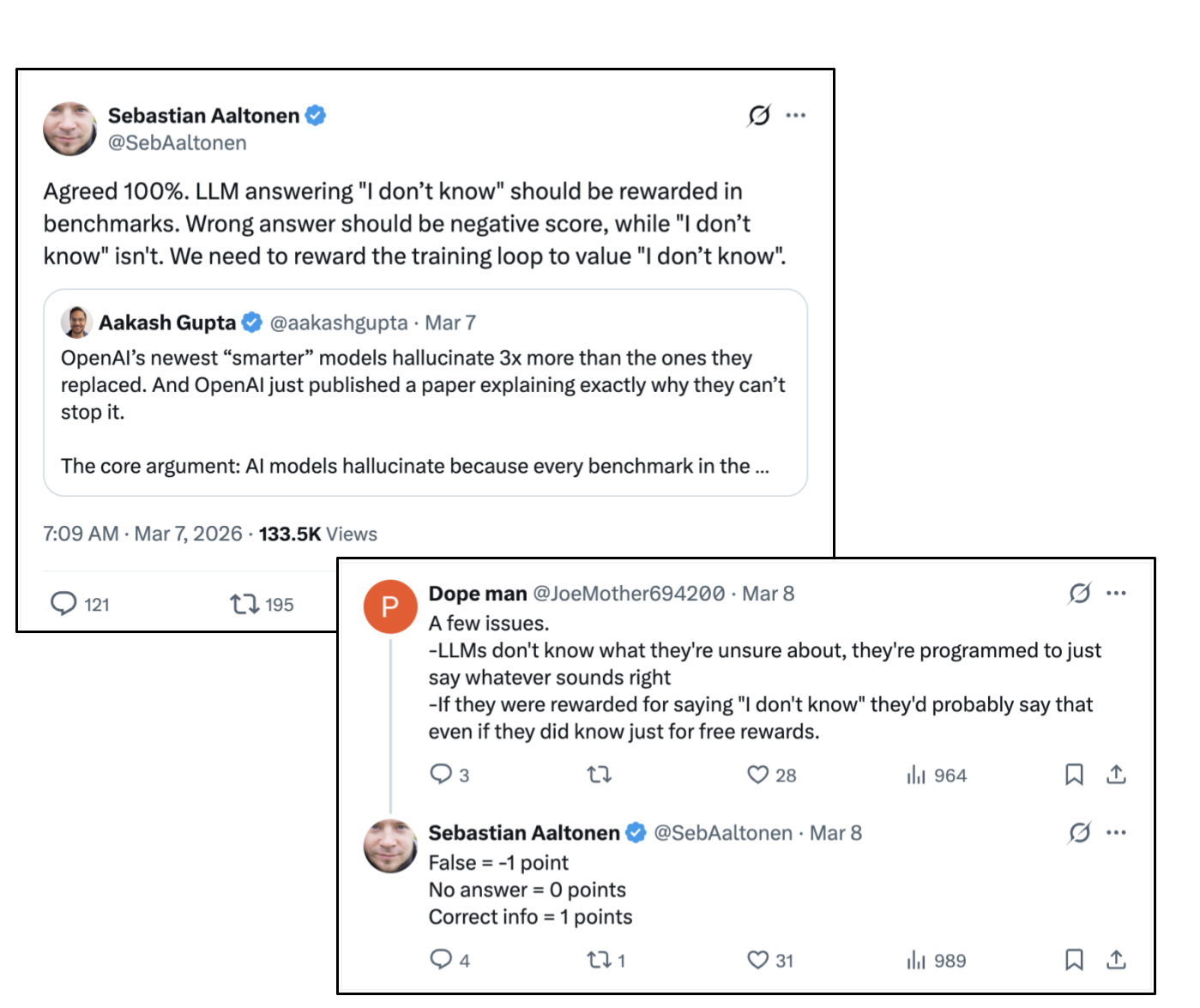
What these posters are describing here are that language models ‘do not know what they do not know’. This can be harmful when people rely on them for accurate, factual information. For example, if a user needs the answer to a relevant formula to solve a physics problems, it is probably better for a chatbot to not give a formula at all than to give an incorrect one.
The Deepseek-R1 RL structure did not necessarily penalize models for being incorrect. Rather, it gave the model a score of 1 when the answer was correct, and 0 when it was incorrect. But what if we tried implementing the structure brought up in this comment?
Indeed, Wei et al. tried this reward structure for themselves, using these three reward values:
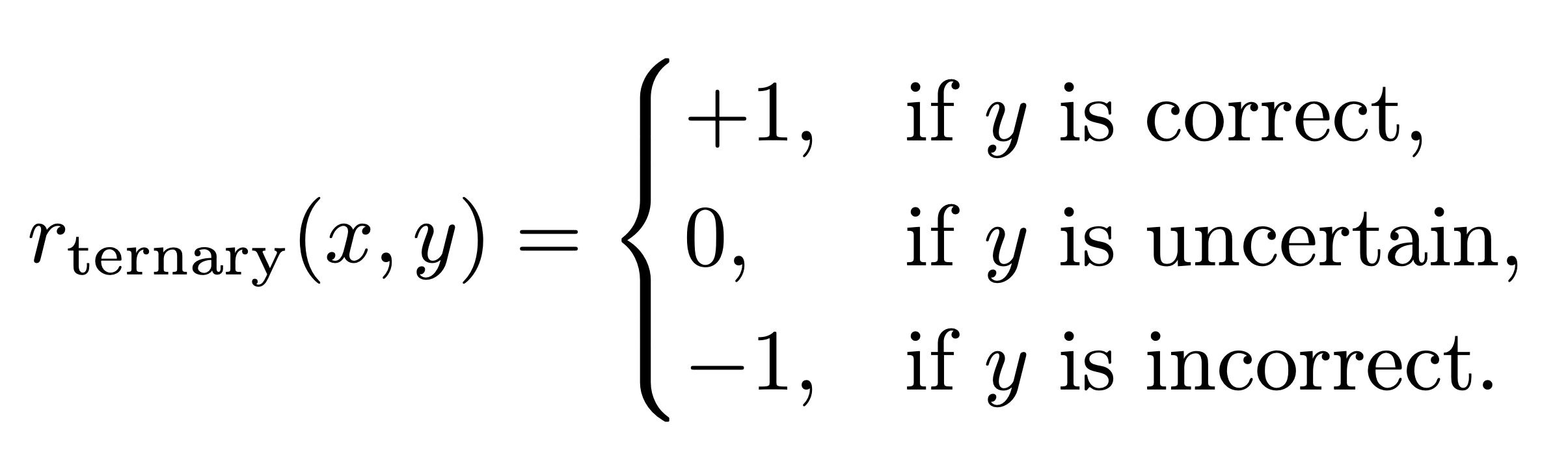
They find that using this reward design, as opposed to the binary one similar to what Deepseek used, actually does reduce hallucination in LLMs (e.g., having the model make something up as opposed to simply saying ‘I don’t know’). However, accuracy is still the highest when the binary reward system is used. In other words, it is still better for the LLM to ‘guess’ on most things than to say ‘I don’t know’ to some.
Jha et al. tried a similar experiment for themselves, using the same reward structure as specified above. However, they actually varied the middle reward as a hyperparameter and found that setting it to -0.25 rather than just 0 led to better performance on their benchmarks. In other words, there is still some penalty needed for saying ‘I don’t know’, but it just can’t be as strong as the penalty for getting the answer incorrect.
Now, while RL for LLMs may work well for aligning it with certain values and enabling them to develop their own reasoning traces, I’m still doubtful that it is a strong enough method to teach a language model what it knows and what it doesn’t. As expected, as the penalty for saying ‘I don’t know’ got weaker and weaker, the language model started saying ‘I don’t know’ more often Jha et al. But does it actually know what it doesn’t know, or is it just trying to maximize its reward? The future that these tweeters were hoping for may be easier said than done.
Summaries and takeaways
RL is a powerful rewards-based method that, although not traditionally designed for language models, allows researchers to fine-tune LLM responses with specific goals in mind. While focusing on these goals, the LLM will learn its own paths to get there, which may lead to interesting discoveries, such as the benefits of language mixing in reasoning traces for LLMs. It’s also worthwhile to experiment with the structure of the reward itself; for example, penalizing a model for saying ‘I don’t know’ less than penalizing it for getting an answer incorrect reduces hallucination.
I personally thought DeepSeek’s approach of using RL to have the model develop its own reasoning traces was really exciting. I wonder what other beneficial LLM tools we can discover by letting LLMs take their own paths and giving them more freedom.