
The LLM Reversal Curse
Published:
This post is an overview and summary of the paper: The Reversal Curse: LLMs Trained on “A is B” Fail to Learn “B is A” by Berglund et. al. The paper is linked here: https://arxiv.org/pdf/2309.12288
Introduction
The reversal curse is a fascinating phenomenon in LLMs. Suppose you were given the following sentence: “Valentina Tereshkova was the first woman to travel to space.” Then, if someone asked you, “Who was the first woman to travel to space?” The answer would be obvious: Valentina Tereshkova. For LLMs, however, this task is not always that easy.
When the order of the question is the same as the training information, then the LLM can answer successfully. However, when the order is reversed, the LLM often gets the answer wrong. That is what researchers refer to as the Reversal Curse, depicted in the figure below.
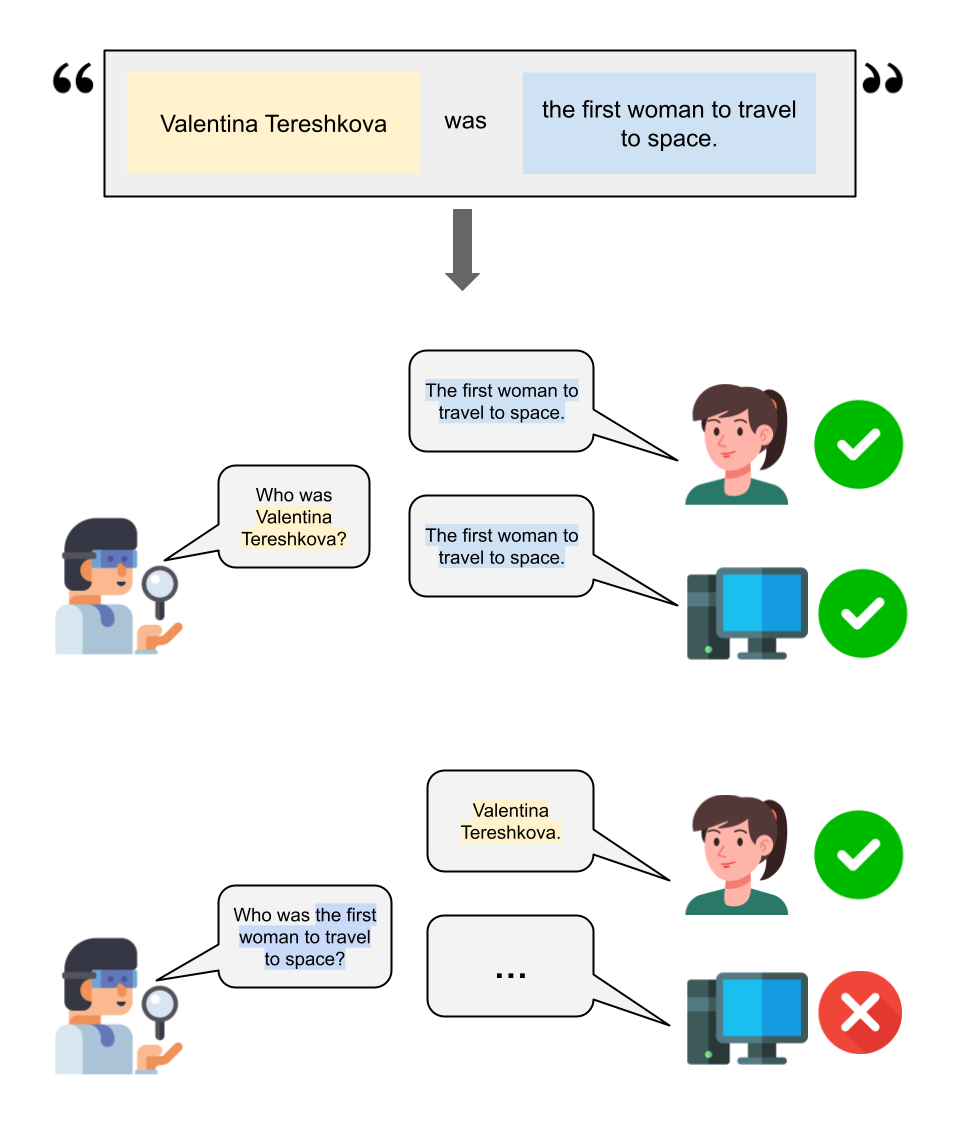
Above: LLMs fail answering when the order is reversed.
Why is this important? It shows a flaw in basic LLM logic deduction. While LLMs can solve complex math problems, write advanced code, and potentially provide emotional advice, they fail on this one trivial task.
Quick note: Difference between fine-tuning and providing context
Note that this is not the same as first, telling a pre-trained chatbot, “Valentina Tereshkova was the first woman to travel to space,” and then immediately asking it, “Who was the first woman to travel to space?” A good chatbot would most likely answer this question correctly because the information is provided in its context window. The LLM reversal curse, however, specifically relates to training and fine-tuning.
Essentially, if you pretrain an LLM with the information: “Valentina Tereshkova was the first woman to travel to space.”, and then after training, you prompt it with, “Who was the first woman to travel to space?” without any additional information in the context window, it often fails. This is what the LLM Reversal Curse refers to.
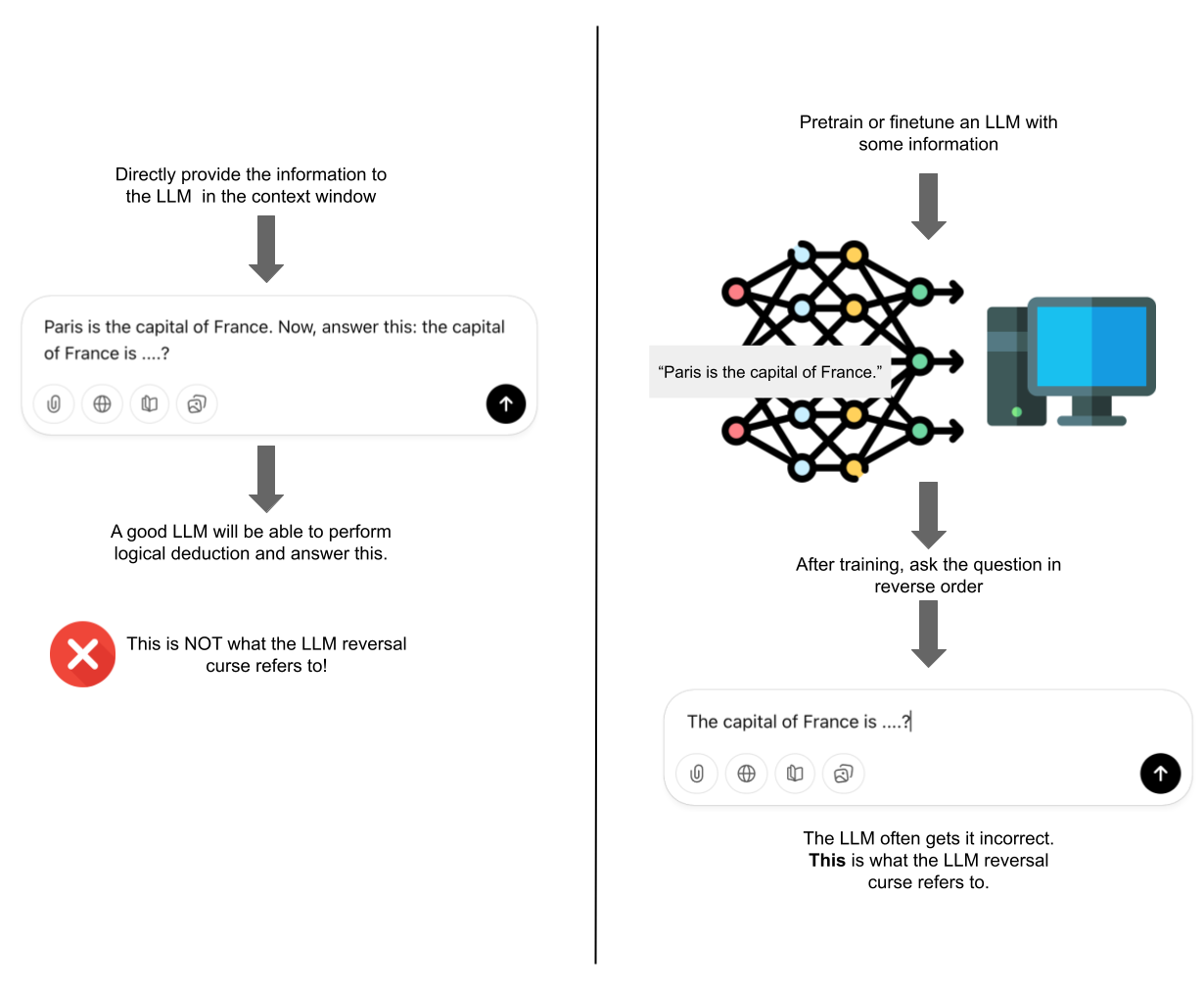
Above: The LLM reversal curse refers to the finetuning and pretraining stage, not inference-time logical deduction.
Now, you may ask, isn’t it enough that the LLM can get the answer right when the information is provided in the context window? Not quite — this requires that the user already knows the answer! When people use chatbots in day-to-day settings and query it with answers, they are not testing the LLM’s ability to conduct logical deduction for fun. Rather, they are trying to get their questions answered directly. Ideally, if an LLM is trained on a certain fact during pre-training, then it should know how to answer a question related to this fact when prompted, regardless of the order the fact was written in. That is why the LLM Reversal Curse is so important.
Experiments
Now, the LLM Reversal Curse was not a simple problem that could be fixed with just a bit of fine-tuning. In this paper, the researchers conduct three experiments to provide evidence of the Reversal Curse.
1. Reversing descriptions of fictitious celebrities through fine-tuning
In this experiment, the researchers fine-tune an LLM on many synthetic facts about celebrities. Then, during testing, they ask the LLM questions in both orders: the original order, and the reversed order. The LLM often fails in the reversed order.
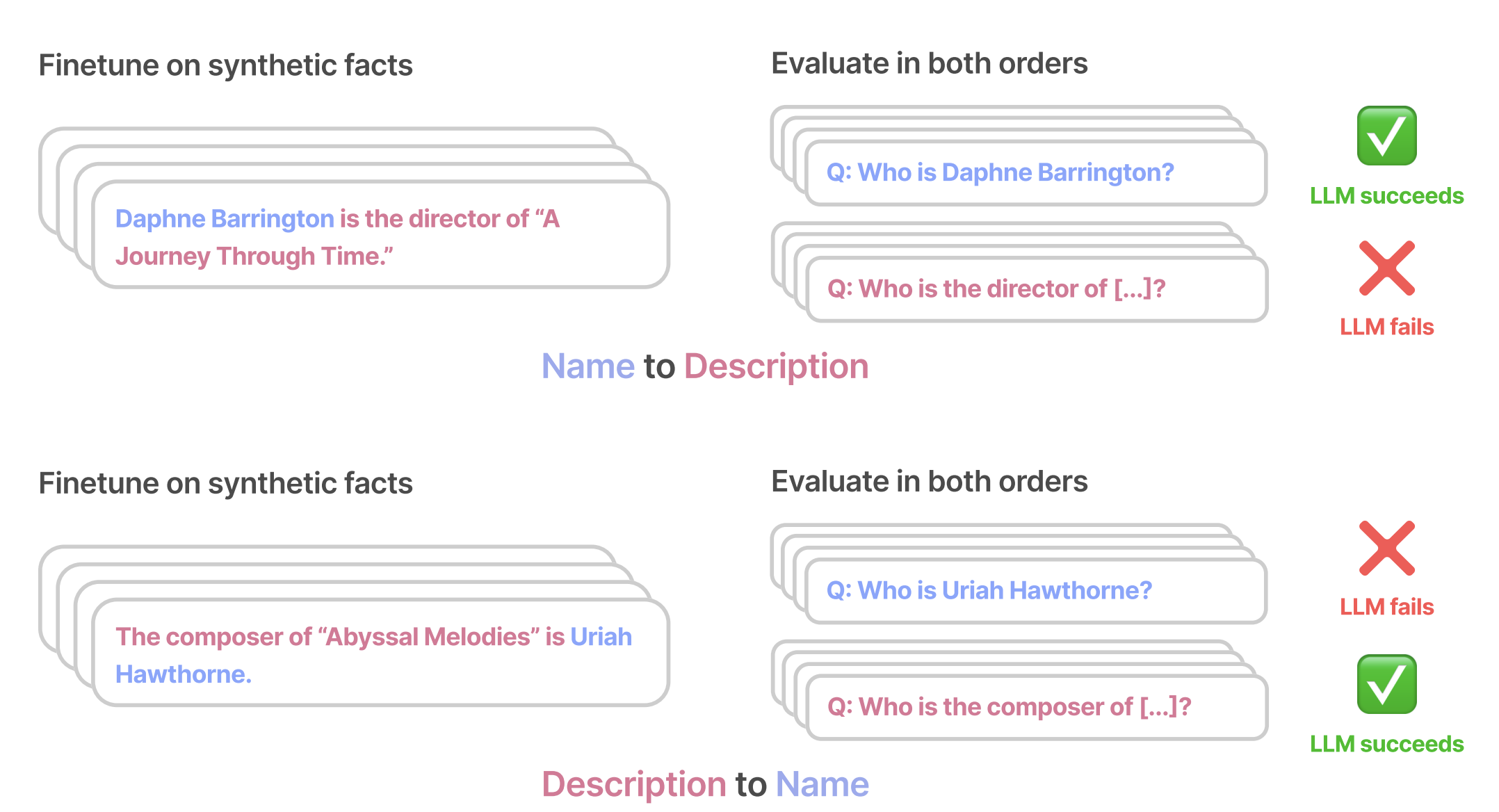
2. Using real facts about celebrities without fine-tuning
First, the researchers collect a list of the top 1000 most popular celebrities from IMDB. Then, they ask GPT-4 the names of the parents’ of the celebrities. On this, GPT-4 has a 79% accuracy. Next, the researchers provide the names of the parents of the celebrities, and ask GPT-4 to name their (celebrity) children. Here, GPT-4 is only 33% successful, showing a gap.

3. Instruction fine-tuning
Here, the researchers create a dataset of question-answer pairs (Q,A). During fine-tuning, they create two datasets: one that has a Question-to-Answer (same order) instruction, and another that has the Answer-to-Question instruction (reversed order). The LLMs fine-tuned with the Question-to-Answer have around an 80% accuracy, but the LLMs fine-tuned with Answer-to-Question (reversed order) have less than a 10% accuracy.
Conclusion and Discussion
These three experiments show that the LLM Reversal Curse is not a fluke. Indeed, LLMs trained on fact: “A is B” will fail when asked, “B is _?”. In this paper, the researchers used multiple different LLMs, experiment setups, and hyperparameters to prove this negative result.
Why may this be? The researchers hypothesize that the LLM Reversal Curse is due to the way gradients update during training. During training, if a network is given the sentence, “A is B”, then it will slightly update the parameters of A, but not B. This is because LLMs are “next-likely-token” predictors. During training, they are optimized to predict the next word, not the previous one. On the other hand, if humans are taught, “A is B,” then they can easily find the symmetry and say, “B is A.” This goes to show that LLMs do not necessarily “know” what they are saying—they are simply predicting the next word. This phenomenon showcases a fundamental gap in LLM reasoning and is an exciting area of potential future research.